Run LLMs locally, without subscribing to paid plans
How to build a ChatGPT-alternative that runs completely local and is100% offline.
Running LLMs (that are open weights or open source) on your own computer has multiple benefits:
- Data Privacy and security: private data remains on your device, as it doesn’t need sending data over the internet to the cloud
- Offline Capability: Once downloaded, models can run without the internet
- No paid subscriptions: Computer and inference is on your machine hence no additional cost for your application (important for token-intensive applications)
- Speed Increase: Depending on your desk/laptop hardware(slower inference, without GPU/NPU), you may see potential speed increase due to no HTTP call overheads
- Customization: Local deployment allows custom modifications to models
There are many open-source tools for hosting open weights LLMs locally for inference - command line interface (CLI) or full GUI based. Few popular are GPT4ALL, Jan.ai, Ollama. It is easy to set up local-first AI, running open-source FMs directly on your computer.
In my experiment (on windows laptop) I chose Ollama and Open WebUI as runners for LLMs.
What is Ollama?
It’s an open-source tool and one of the most active inference server in the open source community. It allows you to run LLMs or SLMs on your local machine, and is optimized for both CPU’s and GPU’s. One can use it to download foundation models directly, and it provides a library of quantized models, which are optimized versions of the models at the cost of some quality loss. That means that you can choose your trade off between speed and quality depending of your needs. It comes with an OpenAI-compatible API, so it can works with many existing applications, and it makes it easy to swap in the model you’re using when working locally or deploying to production.
Ollama runs as a native Windows application (wsl not needed), and has support for NVIDIA and AMD Radeon GPU.
Set up instructions at: Ollama
List of models available for download on Models Library
[1/25/2025 update], Deepseek-r1 is among the most popular with 1.4MN+ pulls
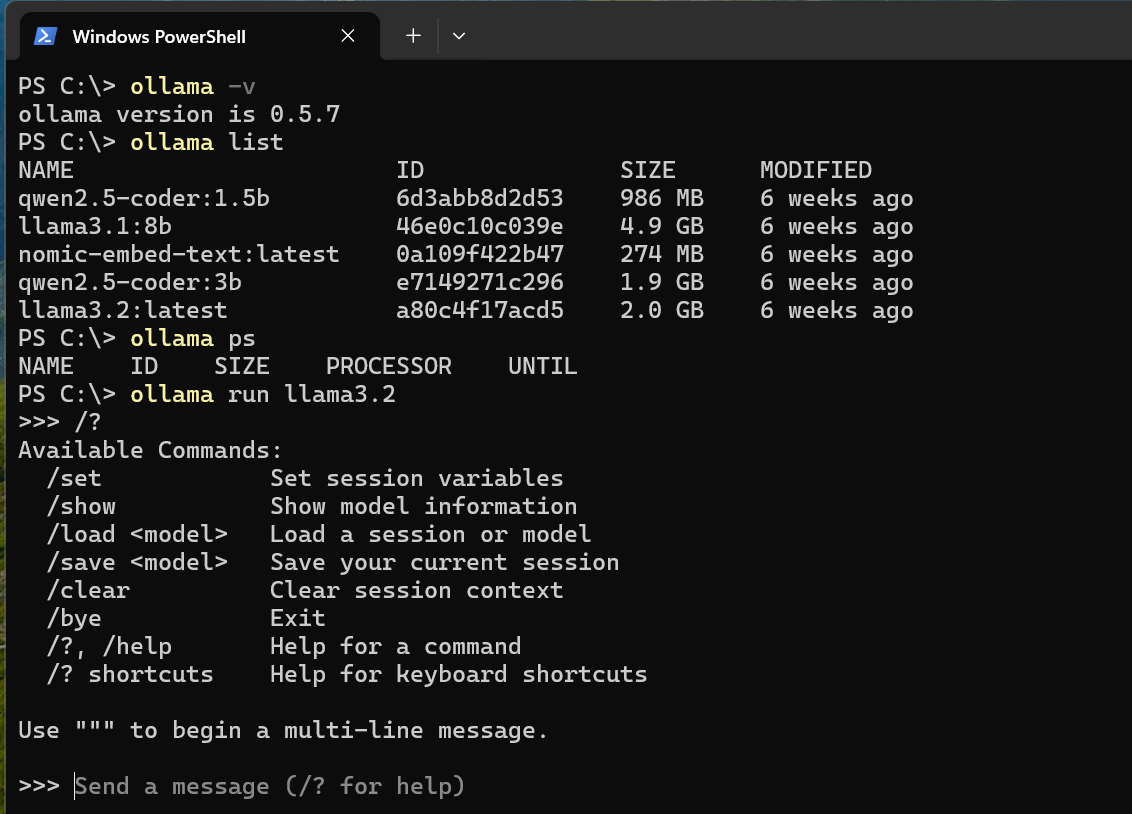
Once Ollama is installed, it is very easy to run from either Windows command-line shells: Command shell or PowerShell
Basic Ollama commands and output:
Examples using Command Line Interface (CLI)
Text Summarization 1 summarizing a large text file e.g. monopoly.txt

Note: The ‘<’ operator didn’t work in Powershell, but works on command shell
Text Summarization 2 summarize Git User Manual (4K lines long) Download user manual here Git User Manual
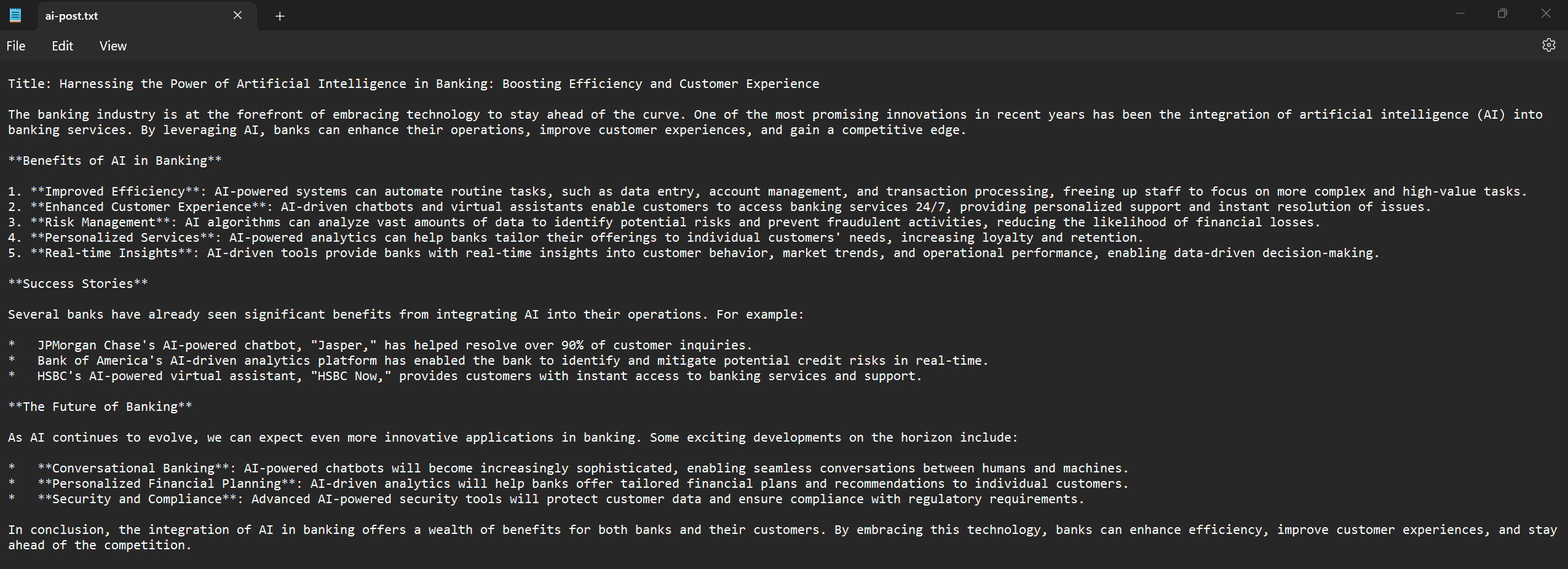
Content Creation: Write an article, or blog post, or create copy

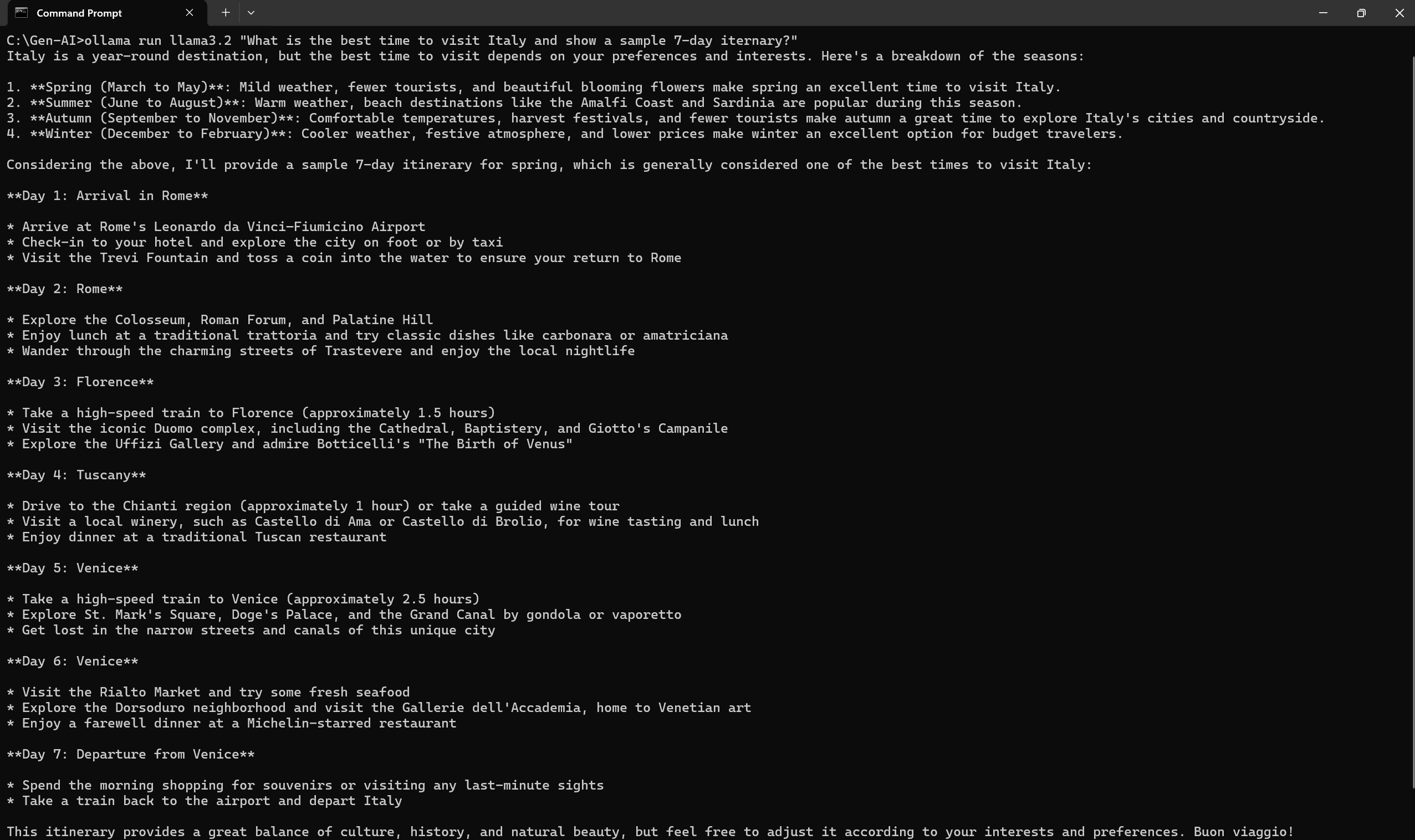
Answering Questions: Ask question and let Gen AI offer recommendation
What is Open WebUI
To enable a GUI or ChatGPT-like interface, I set up Open WebUI. Open WebUI is an extensible, feature-rich, and user-friendly self-hosted AI platform designed to operate entirely offline. It supports various LLM runners like Ollama and OpenAI - compatible APIs, with built-in inference engine for RAG, making it a powerful AI deployment solution. If your computer has Nvdia GPU, it leverages CUDA acceleration. Open Web UI is primarily installed through a Docker image on Windows because Docker provides a consistent environment to run the application, isolating dependencies and simplifying deployment across different Windows systems, ensuring that the application works seamlessly regardless of the specific Windows configuration or installed libraries, minimizing compatibility issues and streamlining the setup process
Set up instructions at: Open WebUI
Examples using Open WebUI Interface
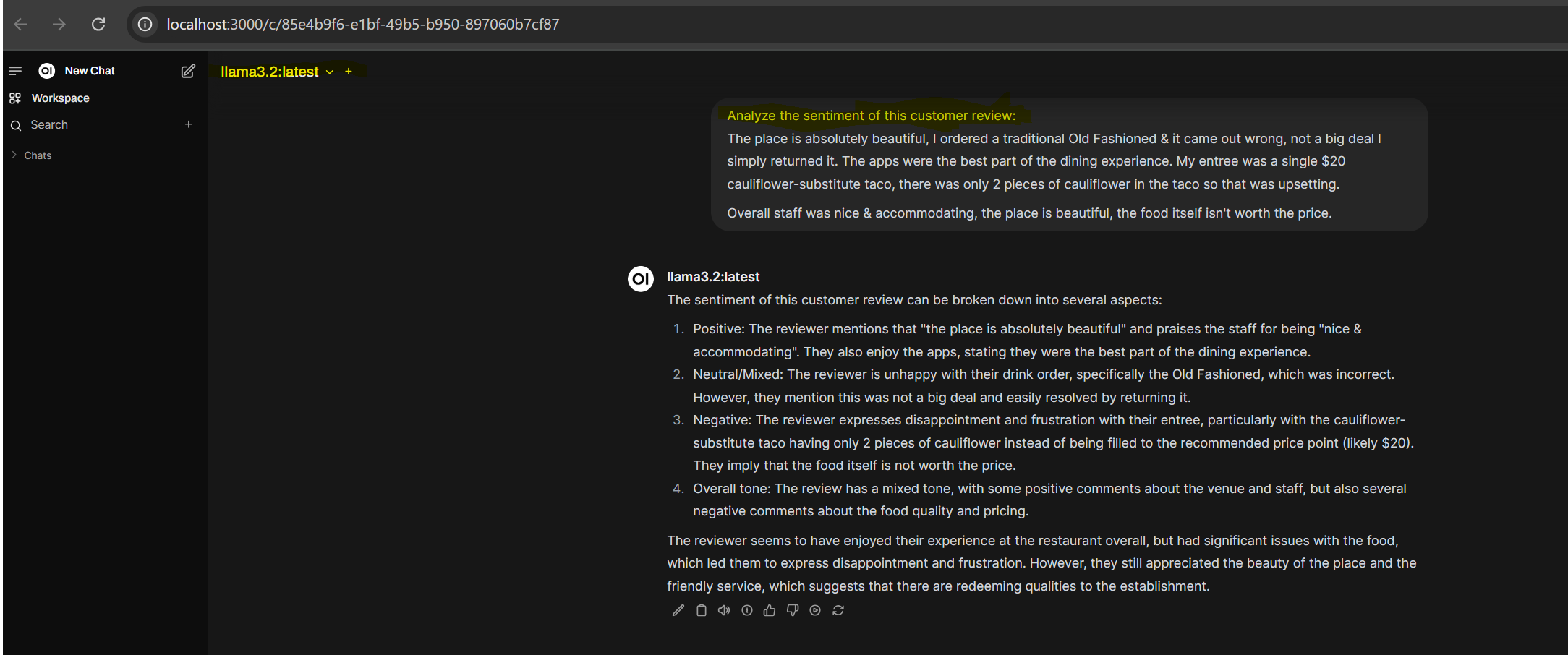
Text classification 1: positive, negative, or neutral sentiment
Text classification 2: Predefine categories News, Opinion, or Review? Upload the article/file to chat and then prompt it to classify 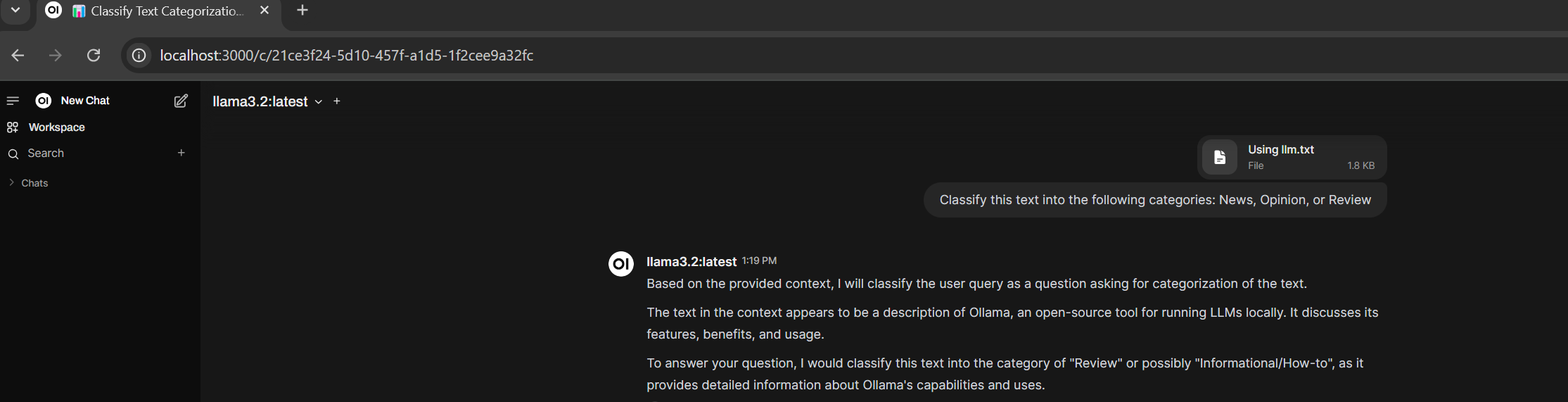
Calling external APIs
1
cURL -X GET “https://api.coinbase.com/v2/currencies” | “Analyze the following API data and summarize key insights.”
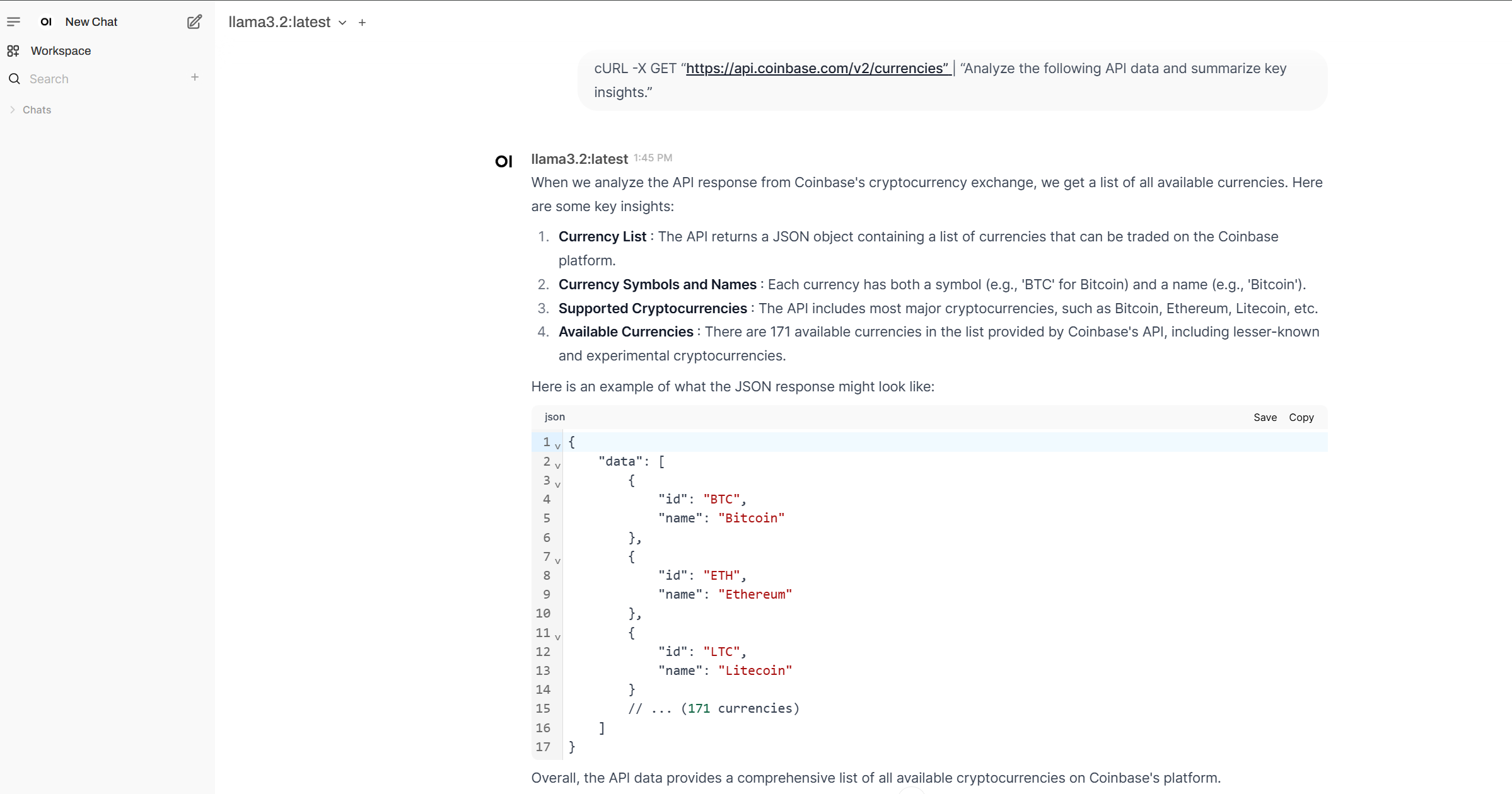
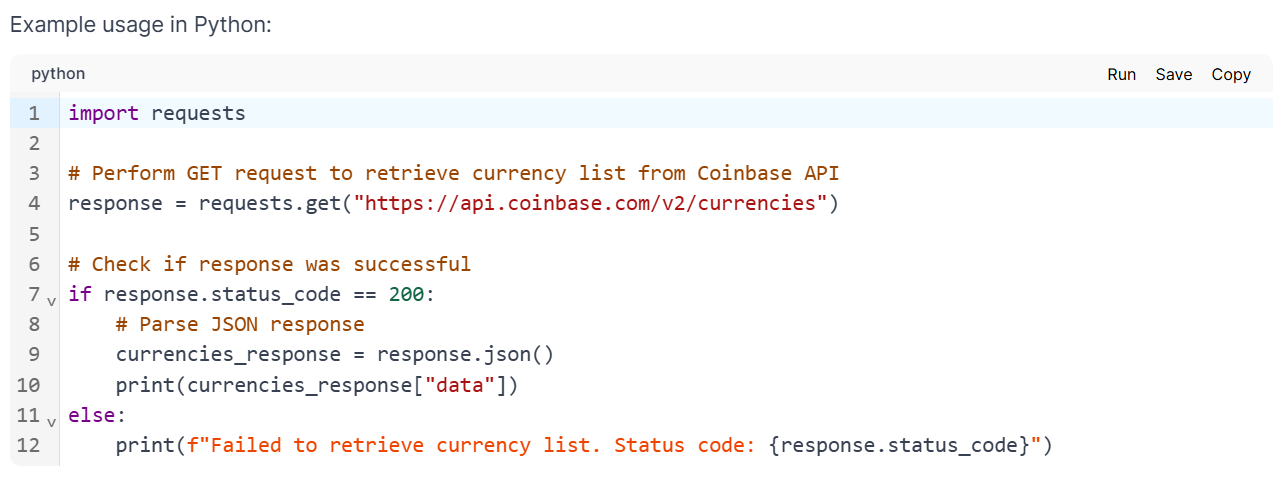
It also provides sample code to use in an application
Coding Assistant
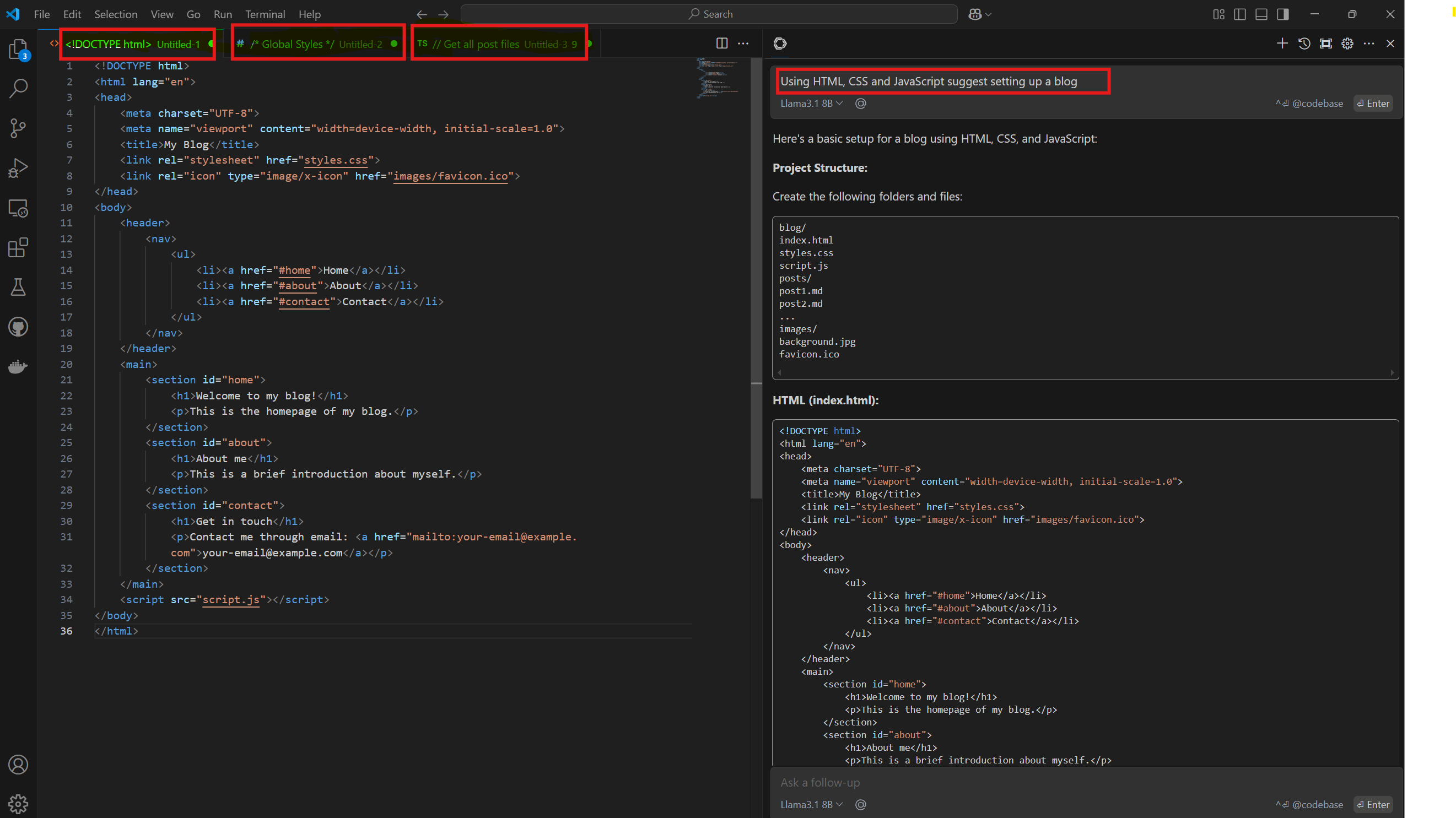
Enterprises are seeing tremendous improvement in software coding productivity by using LLMs. One such local-first AI coding assistant is Continue. It can be set up to run inside of VS Code or Jet Brains IDE enabling:
- Chat to understand and iterate on code in the sidebar
- Autocomplete to receive inline code suggestions as you type
- Edit to modify code without leaving your current file
- Actions to establish shortcuts for common use cases
Coding Assistant Example: Create a blog site At the Continue prompt in VS Code, type Using HTML, CSS, JScript suggest setting up a blog site and press Enter. Continue will generate code for you based on your requirements. The generated code includes HTML, CSS, JavaScript, and other set up instructions to create a blog site. You can then open the generated code in VS Code and start building your blog site. Continue also provides features such as refactoring, debugging, and testing to help you improve your coding skills. It is a powerful tool for developers who want to save time and increase their productivity by using LLMs.